

基于领域数据和用户行为的分词、词性标注、命名实体识别,用于定位基本语言元素,消除歧义,支撑自然语言的准确理解。
“从深圳南山区科技园科苑北路寄到上海静安区,大概多长时间?”
分析结果:
从(介词)|深圳(地名)|南山区(地名)|科技园科苑北路(地名)}寄到(动词)|上海(地名)|静安区(地名), 大概(副词) 多长时间(时间名词)?


依托网络上海量的开源数据和壹鸽智能语音系统产生的优质对话数据,利用深度学习技术,通过词语的向量化来实现文本的可计算,实现平台的语义挖掘、相似度计算等应用。
通过训练的方法,将语言词表中的词映射成一个长度固定的向量。词表中所有的词向量构成一个向量空间,每一个词都是这个词向量空间中的一个点,利用这种方法,实现文本的可计算。
比如:
在领域内,意义很相近的两个分词的词向量,其cosin结果较高。
例如1“快递”“包裹”两个分词的含义很相似,通用的cosin>0.7,领域内的cosin>0.9,证明两个词的距离较近。
例如2“发货”“签收”两个分词的含义不是很相似,则cosin值比较低,表示两个词的距离较远。
基于词法分析和词语向量化表示来计算两个词之间的语义相似度,帮助快速实现问题检索、答案推荐以及排序等应用。
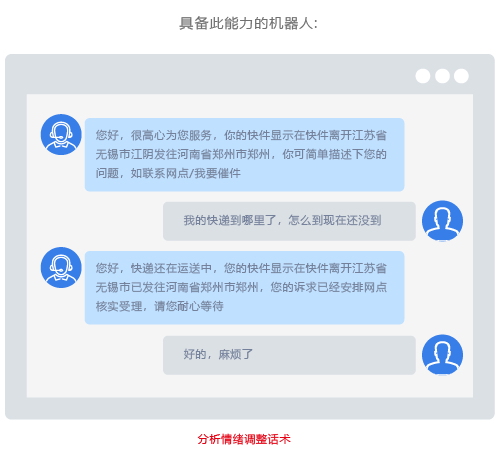
在用户对话过程中,结合客户对话的声学特征以及文本里蕴含的情绪特征,帮助企业更全面的把握产品体验、监控客户服务质量等。

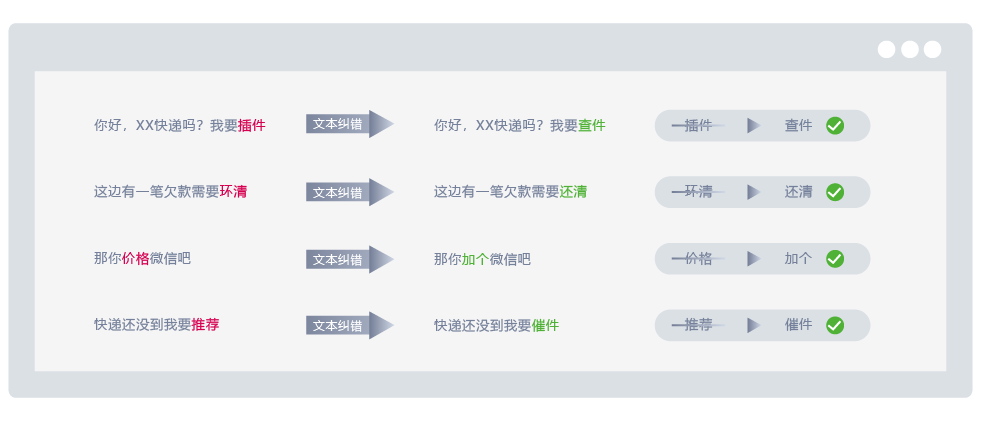
在与客户打电话的场景中,因为各种环境及电话信号的因素,语音识别的准确度远低于实验室,语音识别转成文本,会经常出现错误的片段,进行错误提示并给出纠错后的结果,对于客户意图的理解有极大的帮助。
纠错办法:
用户经常在对话时,语音识别将客户说的话识别错误,通过分析海量对话内容的形式和特征,可自动纠正语音识别后的结果,进而给出更符合用户需求的答案,有效识别错误对用户真实需求的影响。
快递物流行业的查件、催件、咨询、下单、派送、收件等业务场景的业务数据, 针对客户的结构化、半结构化、无结构的多源异构数据进行智能化知识图谱的建设,在文本纠错,上下文关联以及意图推理上能实现更好的效果,极大的优化电话机器人在理解客户真实意图的能力。

针对VoIP语音信号专门训练,并通过场景化识别优化,为快递物流、生产制造业等行业提供语音识别的解决方案,准确率达到85%以上。
客户边说边转文本, 采用流式传输方式,响应速度比通过录音转换成文本更快(响应速度至少提升20%)
企业可以提供企业相关的录音和关键词信息,训练企业专属的识别模型。提交的语料越多,语音识别效果的提升也越明显。


提供真人语音库、全机器合成语音库、真人与机器合成混合语音库三种模式, 提供定制,满足不同行业应用需求.
常规的方法,是将文字合成语音后,再提供的语音平台去播放。较长的文字合成语音需要1s左右,壹鸽采用流式合成的方式,边转边播放,不论合成的文字有多长, 200ms~300ms内就开始播放,速度和流畅性有极大的提升。

 联系我们
联系我们二维码关注
 官网二维码
官网二维码 微信二维码
微信二维码